Pronósticos con VAR
Contents
from bccr import SW
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn')
from statsmodels.tsa.api import VAR
import statsmodels.api as sm
from itertools import permutations
8.4. Pronósticos con VAR#
Recordemos que
Suponga que \(\Phi\) ha sido estimado con datos hasta \(t=T\).
El mejor pronóstico del sistema \(s\) períodos adelante es
El error de pronóstico es
y su varianza (MSPE) es
Pronósticos de largo plazo con VAR#
Partiendo de
recordamos que:
\(\hat{y}_t\equiv y_t-\mu\)
si el VAR es estacionario, \(\lim\limits_{s\to\infty}\Phi^s = 0\).
Entonces el pronóstico de largo plazo
es decir
en el largo plazo el VAR volverá a su equilibrio estacionario.
Descomposición de la varianza del shock reducido#
Recuerde que los errores reducidos están relacionados con los estructurales por \(\epsilon_t = \Gamma_0^{-1}\varepsilon_t\).
Sea \(\Gamma_0^{-1} \equiv A =\MAT{a_1&\dots&a_n}\), con \(a_i\) la \(i\)-ésima columna de \(i\).
Entonces
Tomando \(\Omega\) del ejemplo al inicio de este capítulo
Entonces \(a'_1 = \MAT{1 & 0.5 & -1}\), \(a'_2 = \MAT{0 & 1 & 0.75}\), \(a'_3 = \MAT{0 & 0 & 1}\) y
Observe que esta descomposición depende del ordenamiento de las variables.
Descomposición de la varianza del pronóstico#
Sustituyendo \(\Omega = \sum_{j=1}^{n} \sigma_j^2 a_ja'_j\) en \(\Var\left[\hat{Y}_{T+s}\;|\; \hat{Y}_{T}\right] \) tenemos
Con esta expresión, podemos cuantificar la contribución del \(j\)-ésimo shock estructural al error cuadrático medio del pronóstico \(s\)-períodos adelante.
Warning
Observe que esto asume que conocemos los parámetros del modelo: ¡No toma en cuenta los errores de estimación!}
Para ello estimaremos un VAR:
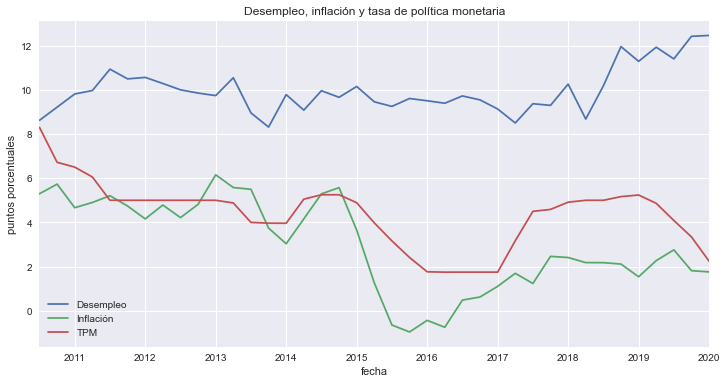
Contamos con una muestra de 39 observaciones trimestrales, de 2010-III a 2020-I.
datos = SW(Desempleo=22796, Inflación=25485, TPM=3541, freq='Q', func=np.mean, fillna='ffill')['2010Q3':'2020Q1']
nombres = datos.columns
fig, ax = plt.subplots(figsize=[12, 6])
datos.plot(ax=ax)
ax.set(title='Desempleo, inflación y tasa de política monetaria',
ylabel='puntos porcentuales');
Escogiendo número de rezagos
El primer paso es escoger el número de rezagos \(p\) del VAR:
model = VAR(datos)
model.select_order(4).summary()
| AIC | BIC | FPE | HQIC | |
|---|---|---|---|---|
| 0 | 1.227 | 1.360 | 3.411 | 1.273 |
| 1 | -1.779 | -1.246* | 0.1693 | -1.595 |
| 2 | -2.121* | -1.188 | 0.1219* | -1.799* |
| 3 | -2.007 | -0.6741 | 0.1411 | -1.547 |
| 4 | -2.002 | -0.2689 | 0.1511 | -1.404 |
En este ejemplo escogeremos un solo rezago, en parte porque tenemos una muestra muy pequeña.
Estimando el VAR
res = model.fit(maxlags=1)
res.summary()
Summary of Regression Results
==================================
Model: VAR
Method: OLS
Date: Thu, 21, Jul, 2022
Time: 00:36:36
--------------------------------------------------------------------
No. of Equations: 3.00000 BIC: -1.30856
Nobs: 38.0000 HQIC: -1.64170
Log likelihood: -115.071 FPE: 0.161485
AIC: -1.82569 Det(Omega_mle): 0.119601
--------------------------------------------------------------------
Results for equation Desempleo
===============================================================================
coefficient std. error t-stat prob
-------------------------------------------------------------------------------
const 2.305139 1.265376 1.822 0.069
L1.Desempleo 0.708084 0.125437 5.645 0.000
L1.Inflación -0.127880 0.087455 -1.462 0.144
L1.TPM 0.243191 0.124252 1.957 0.050
===============================================================================
Results for equation Inflación
===============================================================================
coefficient std. error t-stat prob
-------------------------------------------------------------------------------
const -0.062525 1.588872 -0.039 0.969
L1.Desempleo -0.003928 0.157505 -0.025 0.980
L1.Inflación 0.827925 0.109813 7.539 0.000
L1.TPM 0.119255 0.156017 0.764 0.445
===============================================================================
Results for equation TPM
===============================================================================
coefficient std. error t-stat prob
-------------------------------------------------------------------------------
const 2.282890 0.964744 2.366 0.018
L1.Desempleo -0.164187 0.095635 -1.717 0.086
L1.Inflación 0.091391 0.066677 1.371 0.170
L1.TPM 0.753419 0.094732 7.953 0.000
===============================================================================
Correlation matrix of residuals
Desempleo Inflación TPM
Desempleo 1.000000 -0.031396 -0.003364
Inflación -0.031396 1.000000 0.307269
TPM -0.003364 0.307269 1.000000
Causalidad de Granger
Al parecer, ninguna variable del sistema causa a otra en el sentido de Granger.
Valores p de hipótesis de causalidad:
granger = pd.DataFrame(
[[res.test_causality(i, j).pvalue for i in nombres] for j in nombres],
index = nombres,
columns=nombres)
granger.index.name = 'Explicativa'
granger.columns.name = 'Dependiente'
granger.round(3)
| Dependiente | Desempleo | Inflación | TPM |
|---|---|---|---|
| Dependiente | |||
| Desempleo | 0.000 | 0.980 | 0.089 |
| Inflación | 0.147 | 0.000 | 0.173 |
| TPM | 0.053 | 0.446 | 0.000 |
Esto no necesariamente implica que no haya relación de causalidad entre las variables: podría haber causalidad contemporánea.
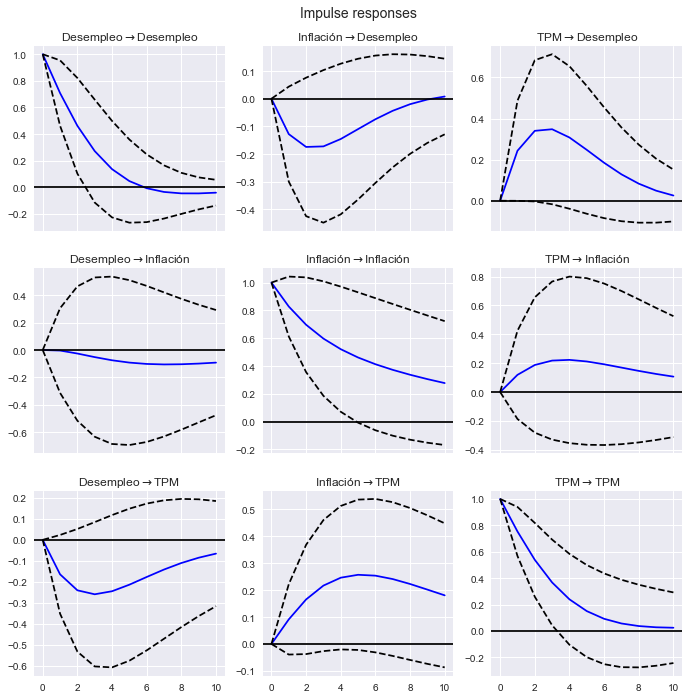
Funciones de impulso-respuesta con impulsos unitarios
Funciones de impulso respuesta, con impulsos unitarios.
res.irf(10).plot(subplot_params={'figsize':[12,4]});
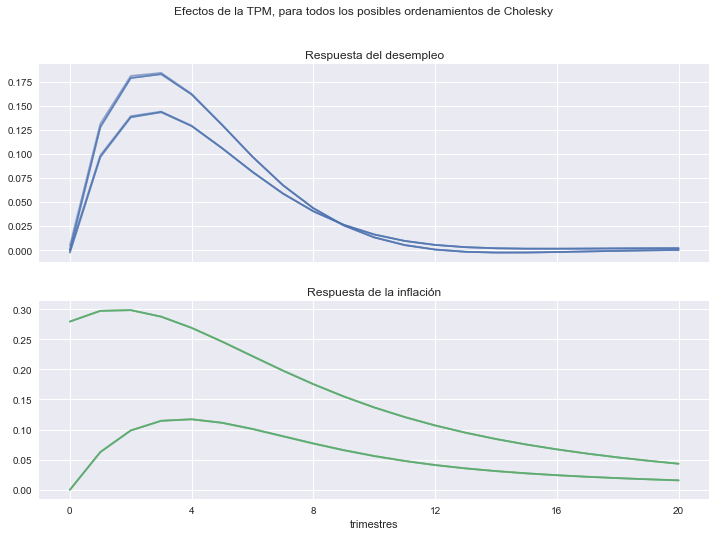
Funciones de impulso-respuesta con impulsos ortogonales
El resultado depende del ordenamiento de las variables en el sistema (Choleski).
def respuesta_politica(orden, h=20):
res = VAR(datos[[*orden]]).fit(1)
irfs = pd.DataFrame(res.irf(h).orth_irfs.reshape(h+1,-1),
columns = pd.MultiIndex.from_product(
[orden, orden],
names=['Respuesta', 'Impulso']
)
)
series = ['Desempleo', 'Inflación']
efectos = irfs.xs('TPM', level='Impulso', axis=1)[series]
reacciones = irfs.xs('TPM', level='Respuesta', axis=1)[series]
return efectos, reacciones
fig1, axs1 = plt.subplots(2,1, figsize=[12,8], sharex=True)
fig1.suptitle('Efectos de la TPM, para todos los posibles ordenamientos de Cholesky')
fig2, axs2 = plt.subplots(2,1, figsize=[12,8], sharex=True)
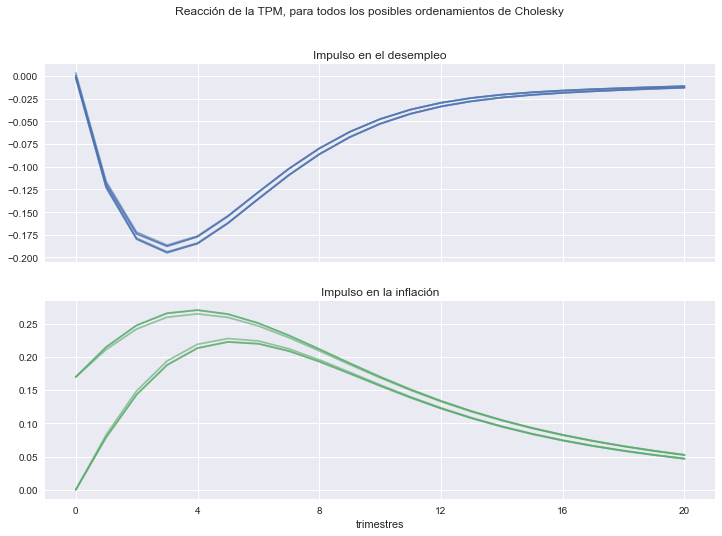
fig2.suptitle('Reacción de la TPM, para todos los posibles ordenamientos de Cholesky')
for orden in permutations(nombres):
efectos, reacciones = respuesta_politica(orden)
efectos.plot(subplots=True, ax=axs1, legend=False, alpha=0.6)
reacciones.plot(subplots=True, ax=axs2, legend=False, alpha=0.6)
axs1[0].set(title='Respuesta del desempleo')
axs1[1].set(title='Respuesta de la inflación',
xlabel='trimestres',
xticks=np.arange(0,21,4));
axs2[0].set(title='Impulso en el desempleo')
axs2[1].set(title='Impulso en la inflación',
xlabel='trimestres',
xticks=np.arange(0,21,4));
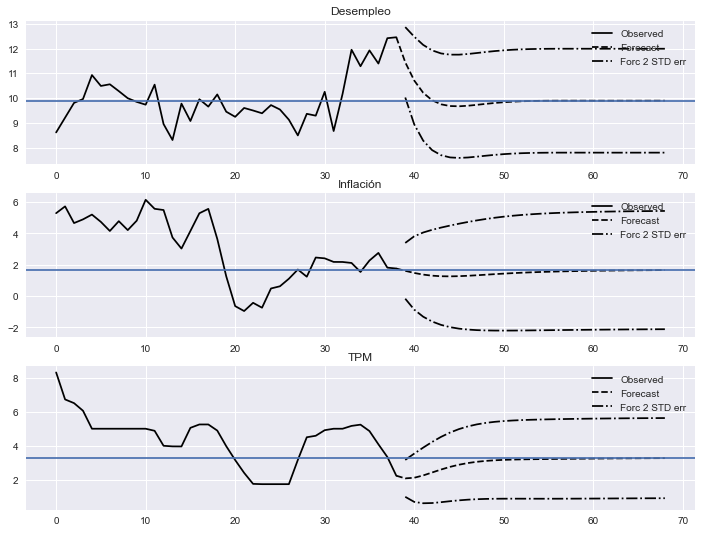
Pronosticando con el VAR
En un VAR estacionario, los pronósticos siempre convergen a la media de largo plazo de cada variable:
fig = res.plot_forecast(30);
fig.set_size_inches([12,9])
𝜇 = np.linalg.solve(np.eye(3) - res.coefs.sum(axis=0), res.intercept)
for ax, v in zip(fig.get_axes(), 𝜇):
ax.axhline(v)
Warning
El valor de \(\mu\) no coincide necesariamente con el promedio simple de los datos.
pd.DataFrame({'𝜇':𝜇, 'Promedio datos': datos.mean()})
| 𝜇 | Promedio datos | |
|---|---|---|
| Dependiente | ||
| Desempleo | 9.899185 | 9.978157 |
| Inflación | 1.693923 | 2.983095 |
| TPM | 3.294578 | 4.365460 |
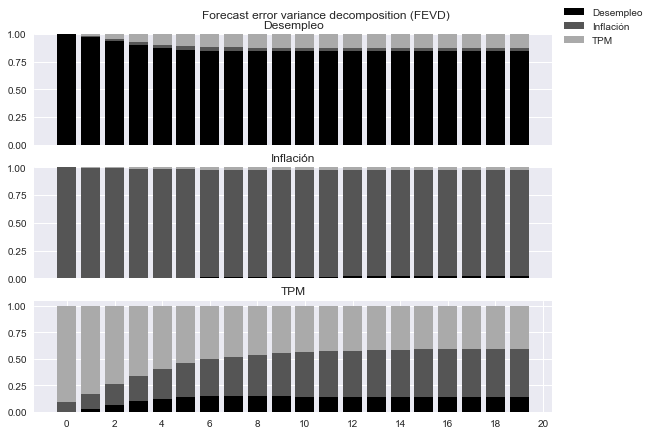
Descomposición de la varianza de pronóstico
fig=res.fevd(20).plot(figsize=[9,6]);
fig.axes[0].set(xticks=[])
fig.axes[1].set(xticks=[])
fig.axes[2].set(xticks=np.arange(0,21,2))
for ax in fig.axes:
ax.set(yticks=[0,0.25,0.5,0.75,1.0])